本文是一篇学习笔记,调研了关于提示工程(prompt engineering)的基础知识、常见提示方法以及应用场景,文末附加相关的在线学习资源。
1. 基础概念
提示工程(prompt engineering, PE)是一门关注提示词(prompt)开发和优化的新兴工程学科。提示词就是用户跟大语言模型(large language model, LLM)的交互途径,可以简单理解为我们给AI的指令,而PE的目的就是如何给出指令,来让LLM更好地完成我们需要它完成的任务。PE相关技能可以在一定程度上提升LLM在多重场景下处理复杂任务的能力,帮助我们利用LLM赋能工作和生活。
使用提示词的渠道一般是通过API(Application Programming Interface)或对话框跟LLM交互。
- 模型参数:给定同样的prompt,调整如下模型参数时,模型的响应(response)可能会变化。
- 温度(temperature):温度参数值越小,模型返回结果确定性越强。反之,温度越高,结果相对更随机,也更多样化和有创造性。根据任务类型不同,设置合适的温度参数,比如对于推理计算任务,设置更低的温度使得模型返回确切的结果;对于诗歌生成任务,调高温度增强创造性。
- Top_p:核采样(nucleus sampling)技术,意思是会考虑top_p概率质量的词元(tokens),参数值较小时会选择最有信心的响应。Top_p和温度参数一般调节一个就行。
- Max Length:控制LLM生成的token数上限,防止生成冗长、无关的响应,控制成本。
- Stop Sequences:字符串,用来阻止模型继续生成token,遇到该字符串即终止。
- Frequency Penalty:对下一个生成的token进行惩罚,通过给重复数量多的token设置更高的惩罚来减少响应中单词的重复。
- Presence Penalty:对重复的token施加惩罚,对所有重复的token惩罚是相同的。
- 提示工程:通过调整优化prompt来使LLM完成期望任务的过程。
- Prompt类型:针对GPT系列模型
- system prompt: 用于设定assistant的整体行为和角色定位,帮助模型了解用户需求。
- user_prompt: 用户输入信息,用于提出问题或查询。
- assistant_prompt: 对LLM如何根据用户问题给出回答进行限定和要求。
2 提示设计
在prompt中增加背景(context,上下文)信息能帮助LLM更好地理解用户意图,从而给出更贴切的回答。背景信息可能是详细描述,也包括案例演示。根据案例有无分成如下几类:
零样本提示(zero-shot prompt):直接提问,不提供示例。
1
2Q:<问题>?
A:单样本提示(one-shot prompt):提供一个示例。
1
2
3
4Q1:<样例问题>?
A1:<样例回答>
Q:<>?
A:少样本提示 (few-shot prompt):提供几个不同的示例。
Prompt的构成要素:并非所有要素都必须,根据具体任务而定。
- 指令:需要模型执行的特定任务和要求。
- 上下文:包含外部信息或额外的上下文信息,引导模型更好地回应。
- 输入数据:用户输入的问题。
- 输出提示:制定输出的类型或格式。
Prompt设计技巧:
- 迭代:从简单的提示词开始,根据效果逐渐调整迭代,添加需要的元素和上下文。如果任务复杂,可以先做分解,从局部开始逐渐完成。
- 指令:将指令放在开头(一说放在结尾),建议使用特殊符号(如###)将指令和上下文分隔开。
- 具体性:任务描述和指令需要具体详细,如果对生成结果的风格等细节有要求,更要注意提示词的具体性。但是要注意具体和冗长的区别,所包含的细节要是必要的。
- 简明直接:不要绕弯子,直截了当表明意图,说要做什么,而不是不要做什么。
Prompt应用场景举例:
- 文本概括:将文章和概念概括成简洁易读的文本摘要。
- 信息抽取(数据结构化):LLM很擅长执行NLP的任务,从给定的自然语言文本中提取出想要的信息。
- 问答:
- 文本分类:比如对文本的情绪进行分类。可能需要给出几个示例帮助LLM更好地完成分类。
- 对话:聊天机器人。给LLM设定角色定位、对话风格,指定意图身份,构建对话系统(比如客服)。也称为角色提示(role prompting)。
- 代码生成:支持多种计算机语言。比如github的Copilot。
- 推理:LLM在数学推理方面表现不佳,需要一些高级的提示工程技术辅助。
- 文本生成:比如邮件、博客代写,但是如果要求质量就需要人的积极参与。
3. 提示方法
基础提示(base prompt):是指直接向LLM提出问题或查询(query)的方法,无需任何工程改进来试图提升LLM的性能。在研究论文中一般用作基线对照来反映其他提示方法的改进效果,也被称为标准提示(standard prompt)或普通提示。
上面提示设计部分提到的零样本和少样本提示都可以用于基础提示中。本部分主要介绍以基础提示作为Baseline,研究人员进一步提出的相对高阶的prompt方法,比如思维链CoT等。
思维链提示(chain-of-thought, CoT):将问题分解为更小、更易处理的子问题,通过一系列中间推理步骤来增强LLMs进行复杂推理的能力。
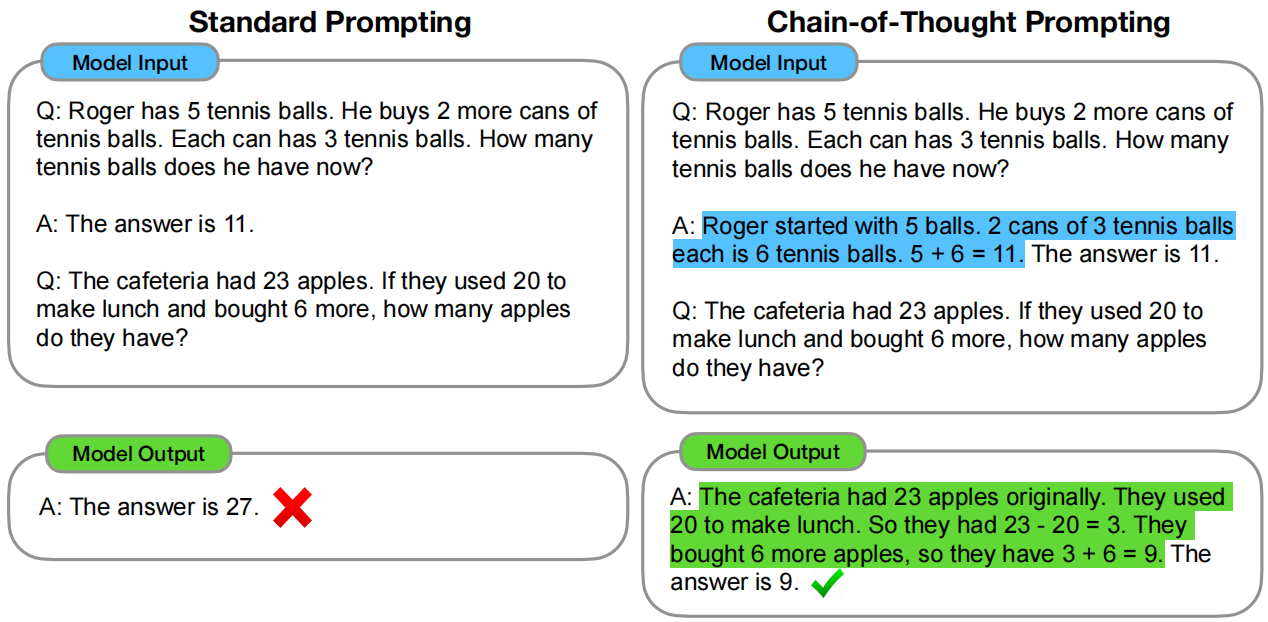
提出论文:J. Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24824–24837, Dec. 2022, Accessed: Jul. 25, 2024. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html
思维链提示的几种类型:
零样本思维链(zero shot chain of thought, Zero-shot-CoT)提示过程:在问题的结尾附加“Let’s think step by step”。
完整的思维链提示其实包括2个步骤,分别是要求使用思维链推理、从思维链推理结果中的提取答案。
单样本或少样本思维链(one shot/ few shot chain of thought):在问题前面或后面加上一个或几个样例及其解决过程的细化步骤。
自一致性:(self-consistency):少样本CoT,同时独立生成多个思维链,取多数答案作为最终答案。多数投票似乎通常具有很好的性能。
思维树(Tree-of-Thought, ToT):
检索增强生成(Retrieval-Augmented-Generation, RAG):
自动推理并使用工具(Autonomous-Reason-and-Action, ART):
自动提示:
ReAct框架:
反思(Reflexion):
4. 在线学习资源
5. LLM产品体验
基于LLM的产品粗略调研,包括产品分类(领域)、创新点、盈利模式和现况等。
| LLM产品名称 | 领域 | 创新点 | 盈利模式 |
|---|---|---|---|
| kimi | |||
| 豆包 |